Scritto dal Team Atelier, con l’aiuto del Team Packaging.
Mageia 10, la nostra nuova versione, è pronta a darvi un nuovo superpotere. Scaricala subito qui, oppure continuate a leggere per scoprire tutti i dettagli.
- La potenza di Mageia 10 si rivela in tutto ciò che permette di fare: può essere usata come desktop o come server, per l’istruzione, lo sviluppo, il lavoro d’ufficio, l’arte, la musica, il gaming, la scienza e molto altro ancora.
- La potenza di Mageia 10 risiede in parte nella vasta gamma di opzioni che mette a disposizione, potendo scegliere tra ambienti desktop completi e window manager.
- La potenza di Mageia 10 si basa, inoltre, sui migliori software per svolgere qualsiasi attività: dalla creatività al tempo libero, dalla sfera personale a quella professionale.
- La potenza di Mageia 10 deriva dalla sua capacità di sfruttare al massimo le potenzialità dell’hardware recente (ad esempio con ROCm) e di quello meno recente, fino a girare persino su vecchi hardware a 32 bit. Non c’è bisogno di aggiornare i componenti del computer per poterne beneficiare.
- La potenza di Mageia 10 si fonda sulla sua tradizione di elevati standard di creazione dei pacchetti, basati su linee guida rigorose, mentoring e test di controllo qualità (QA).
- La potenza di Mageia 10 è garantita dal monitoraggio costante delle minacce alla sicurezza e dalla loro rapida risoluzione.
In fin dei conti, la potenza di Mageia 10 – il segreto del suo vero potere – scaturisce da voi, la sua appassionata comunità di utenti e collaboratori: dagli sviluppatori agli artisti, da chi dona denaro a chi dona il proprio tempo, sia direttamente sia semplicemente segnalando i bug. Siete voi, la nostra comunità, a guidarne la forma e l’evoluzione di Mageia, per garantire che risponda alle vostre reali esigenze e al vostro modo di lavorare.
È giunto il momento di dare un’occhiata all’interno…
Mageia 10 include versioni più recenti di migliaia di pacchetti; queste nuove versioni spesso comportano nuove funzionalità, oltre alle consuete correzioni di bug. Puoi trovare alcune delle novità principali nelle Note di rilascio. Puoi inoltre consultare l’elenco dei pacchetti disponibili nel Database delle applicazioni di Mageia, ordinato per gruppo, e scegliere se visualizzare tutte le applicazioni o solo quelle grafiche. Clicca su un’applicazione per ottenere ulteriori informazioni e visualizzarne uno screenshot.
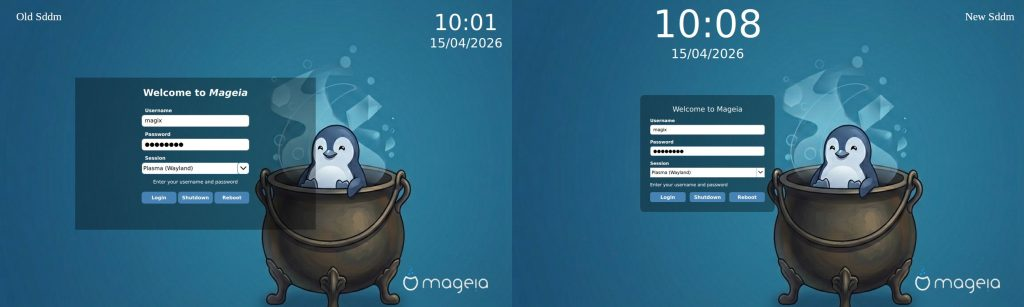
Sebbene Mageia 10 continui a sfoggiare con orgoglio i suoi colori tradizionali, qua e là si notano alcuni miglioramenti grafici. Ad esempio, la nuova schermata di accesso SDDM, visibile in basso a destra, offre un assaggio della cura dei dettagli presente in questa versione.
Questa nuova versione prosegue la tradizione di Mageia di offrire diverse opzioni di installazione: il classico DVD, le immagini live (solo per nuove installazioni) e le installazioni via rete. Prendendo come esempio le immagini live, ecco alcune delle numerose migliorie offerte da Mageia 10:
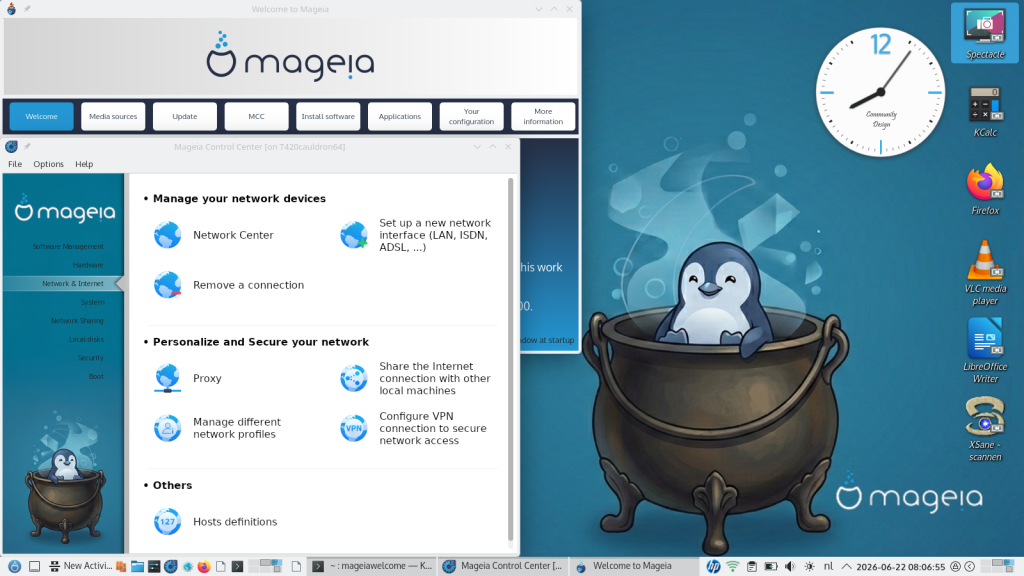
Aggiornamenti per tutti gli ambienti desktop installabili con Mageia (scegli quello che preferisci, oppure installali tutti sullo stesso computer!). Mageia offre un’ampia varietà di ambienti desktop popolari e leggeri, che puoi installare in qualsiasi momento tramite il nostro centro software o dal terminale (se sei un utente più esperto). Potete quindi scegliere tra Plasma KDE 6.5.5, GNOME 49.0, XFCE 4.21, LXDE, LXQT (ora con un’opzione Wayland), Enlightenment, IceWM, MATE, Fluxbox, Cinnamon, Sugar o i più recenti compositori Wayland come labwc, niri, sway e hyprland. Se installati insieme a un ambiente desktop, i gestori di finestre compaiono come sessioni alternative nel menu di accesso del gestore di display: oltre 20 ambienti desktop e gestori di finestre disponibili per l’installazione con un semplice clic. Maggiori informazioni sono disponibili qui.
Aggiornamenti per le principali suite per l’ufficio (ad esempio LibreOffice 26.2.3.2), browser web (ad esempio Firefox 140.11.0esr), strumenti multimediali, software di editing di foto e video, strumenti di sviluppo (ad esempio gcc 15.2.0, rust 1.95.0, Python 3.13.13 o Perl 5.42.0, Git 2.52), i demoni di server (ad es. Postfix 3.9.10, Apache 2.4.67, Docker 28.5.2, PostgreSQL 18.4) e altro ancora, tutti basati sul nostro kernel Linux LTS 6.18.35.
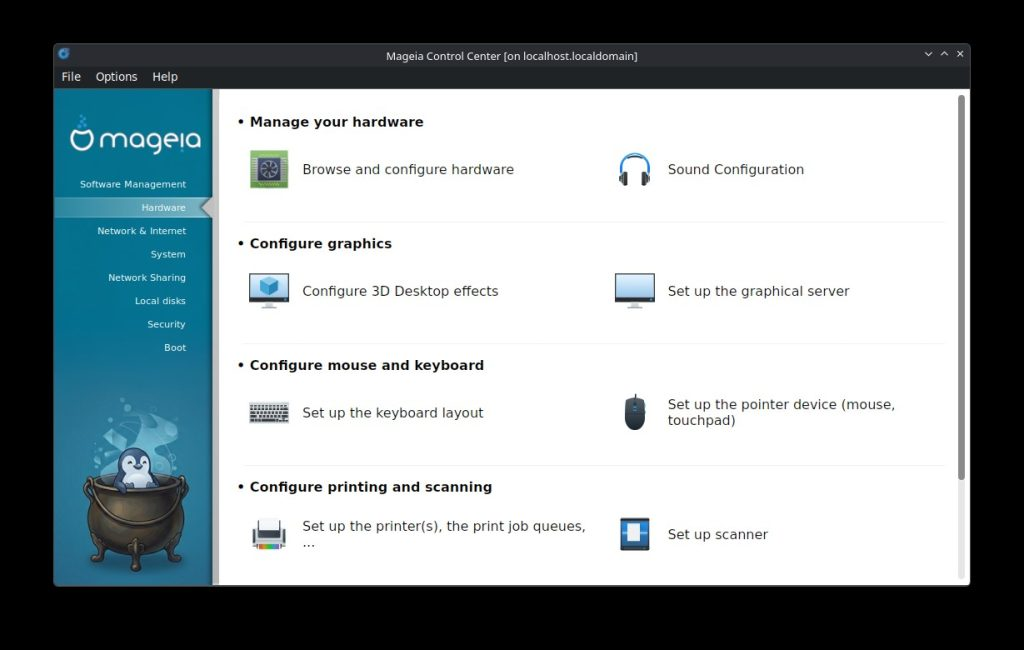
Aggiornamenti e ottimizzazioni dei nostri strumenti Mageia. Sentiti un vero esperto con il nostro Mageia Control Centre (MCC), urpmi, gli aggiornamenti grafici e il supporto per dnf, per gestire e configurare molte parti del sistema, oltre al supporto per l’ambiente desktop che preferisci! Puoi visualizzare facilmente tutto l’hardware rilevato in un’interfaccia grafica, controllare i driver, configurarne le impostazioni (se sei un utente esperto), installare stampanti e molto altro ancora!
Inoltre, grazie alla nostra compatibilità con DNF, Flatpak e AppImage, hai accesso a una vasta gamma di software. Maggiori informazioni sulle applicazioni disponibili sono disponibili qui sul nostro wiki.
Senza dimenticare il punto di forza di Mageia: è una distribuzione comunitaria, realizzata dai suoi utenti. Questa versione non sarebbe stata possibile senza tutti i nostri volontari: i responsabili dei pacchetti, gli sviluppatori, gli amministratori di sistema, i tester QA, i traduttori, gli artisti, gli esperti legali, i team che si occupano del sito web, dei forum e della documentazione, e tutti coloro che hanno contribuito a renderla possibile. Unisciti alle nostre comunità globali, ai forum, ai gruppi Matrix, a Telegram o all’IRC per migliorare la tua fantastica distribuzione. Fai parte di noi, partecipa.
Se hai bisogno di ulteriori informazioni sull’installazione di Mageia o sul Centro di controllo di Mageia (MCC), consulta la nostra documentazione ufficiale. Nelle Note di rilascio troverai anche le istruzioni per l’aggiornamento da Mageia 9. Naturalmente, sul nostro wiki è disponibile ulteriore documentazione. Consulta anche il nostro Bugzilla, dove teniamo traccia dei problemi.
Scopri tutta la potenza di Mageia 10. Scaricala. Buon divertimento!
Mageia 9 sarà supportata fino al 30 settembre 2026.